LLäMmlein 7B, 1B & 120M

NEW: A 7B LLäMmlein is now also available!
Julia & Jan at our chair created three German-only decoder models, LLäMmlein 120M, 1B & 7B, from scratch.
The project involved several key steps, including extensive data preprocessing, the creation of a custom tokenizer, and optimization of training settings to effectively utilize available hardware. Throughout the training process, various checkpoints were saved and analyzed to monitor the models' learning dynamics. Compared to state-of-the-art models on the SuperGLEBer benchmark, both LLäMmlein models performed competitively, consistently matching or surpassing models with similar parameter sizes. The LLäMmlein 1B also showed comparable results to larger models, with no significant performance difference observed.
We also released an encoder version called ModernGBERT, including a Preprint and corresponding LLämmlein2Vec versions.

Resources
Paper@ACL now available, as well as a c't-article
Download the base models (120M, 1B & 7B) (including a Bavarian preview!) and chat-tuned models (1B & 7B)!
We also publish intermediate training checkpoints for our base models, which can/will be found e.g. here for the 120M model (drop down menu "main" top left).
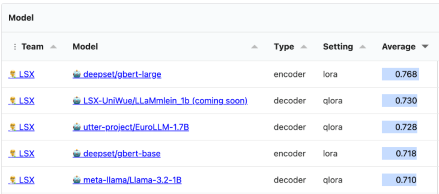
SuperGLEBer Benchmark Ergebnisse
Our LLäMmlein 1B ranks as the best evaluated decoder model overall on our SuperGLEBer benchmark! And compared to state-of-the-art models on our benchmark, both LLäMmlein models performed competitively, consistently matching or surpassing models with similar parameter sizes.
Data Take Down
Wenn Sie die Löschung spezifischer Daten aus einem unserer Datensätze, sowie aus dem Trainingsdatensatz für zukünftige Modelle beantragen möchten, senden Sie bitte eine E-Mail an llammlein<at>informatik.uni-wuerzburg.de. Bitte beachten Sie, dass ein Löschen von Daten aus Sprachmodellen ist nicht möglich. Bitte geben Sie in Ihrer E-Mail Ihren Namen und Ihre Organisation/Firma (falls zutreffend), den Datensatz (einschließlich Version und Veröffentlichungsdatum), die spezifischen Datenpunkte, um die es geht, den Grund für Ihre Anfrage sowie Ihre E-Mail-Adresse und Telefonnummer an. Nachdem wir Sie und Ihre Anfrage authentifiziert haben, wird der Lehrstuhl X für Data Science der Universität Würzburg Ihre Anfrage prüfen und Ihnen antworten.
Bitte beachten Sie: Der Lehrstuhl X für Data Science wird Ihre Anfrage auf Basis der geltenden Gesetze (insbesondere der DSGVO) prüfen und über die Löschung der Daten entscheiden.
Dies ist ein Open-Data-Projekt des Lehrstuhls mit permissiver (offener) Datenlizenzierung. Wenn der Lehrstuhl X Daten als Reaktion auf eine Löschungssanfrage löscht, nehmen Sie bitte zur Kenntnis, dass wir möglicherweise nicht in der Lage sind, Daten zurückzuholen oder zu löschen, die sich bereits außerhalb der vom Lehrstuhl verwalteten Datensätze befinden (z.B. bei Dritten, die den Datensatz heruntergeladen haben). Der Lehrstuhl kann ebenfalls keine Zusicherungen oder Garantien abgeben, dass die Daten außerhalb der eigenen Datensätze oder aus den Sprachmodellen gelöscht werden können.